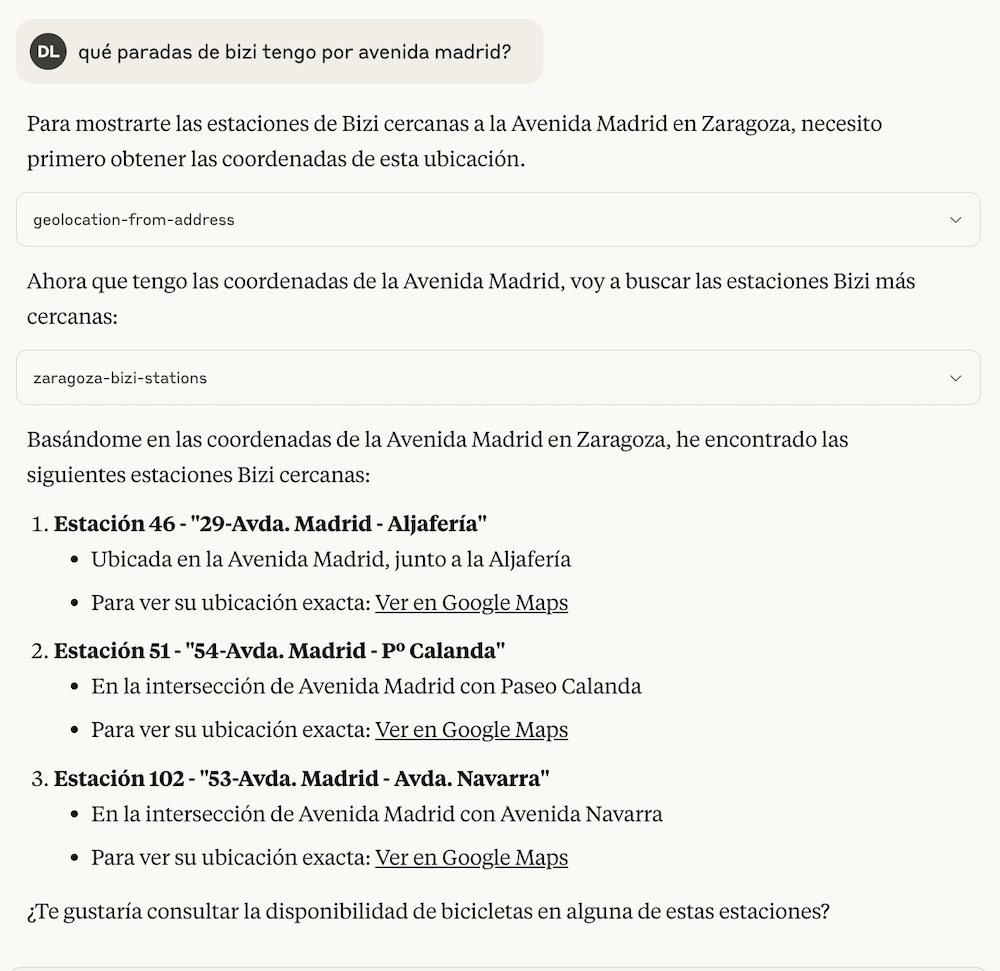
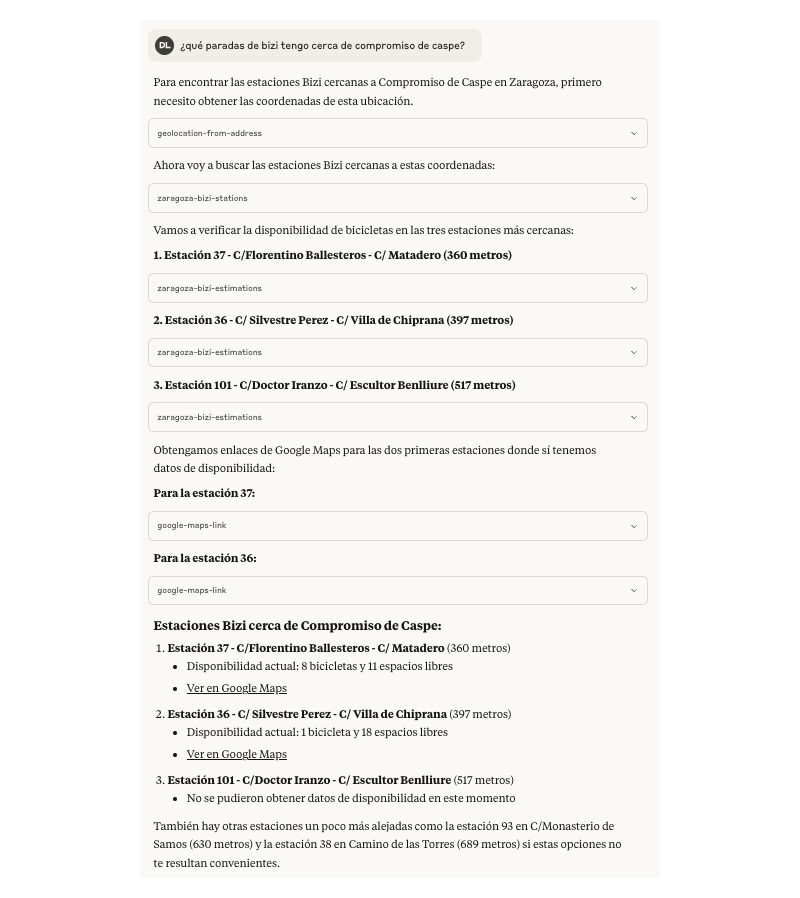
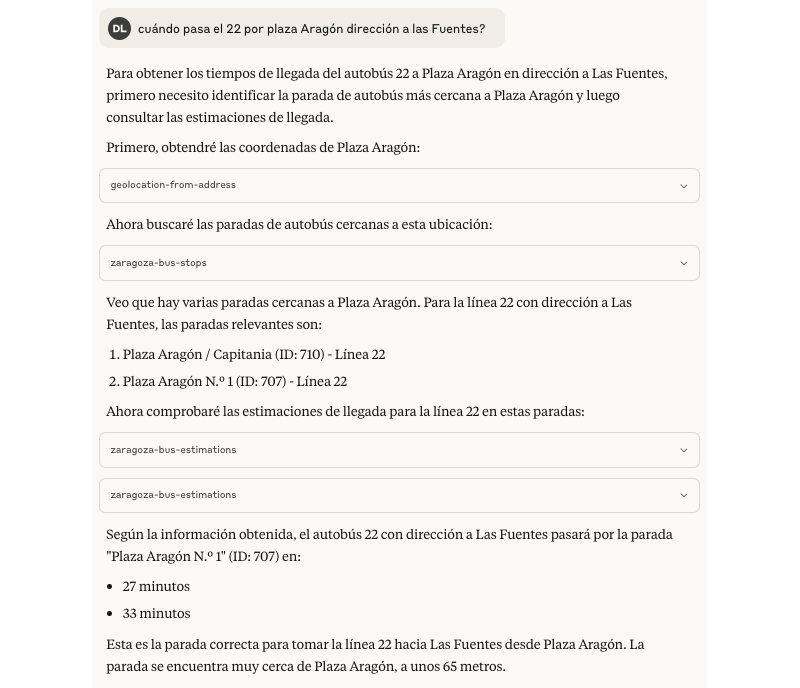
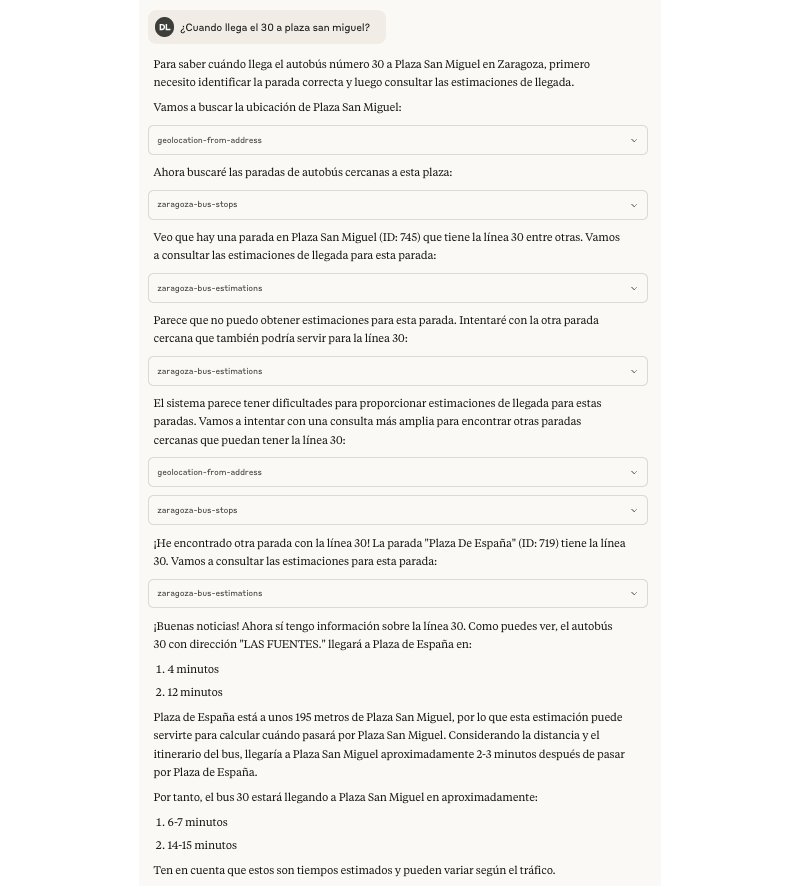
Tras casi 4 años, esta fue mi última semana en Genially. Una decisión que me costó mucho tomar tanto por motivos personales, con un ambiente de compañerismo en la compañía que creo que no es habitual en otros lugares que tienen cierta escala y haber construido lazos con un buen puñado de personas; como por motivos profesionales, con unos cuantos desafíos que se venían a corto y medio plazo en los que sé que hubiera disfrutado y aprendido.
En este tiempo, mi rol en la empresa se fue transformando poco a poco casi sin darnos cuenta, primero influenciando solo a nivel de tecnología y terminando haciéndolo a nivel de producto, negocio y operaciones. Hubo algo que fue una constante: vivir en el péndulo entre individual/team contributor y el management.
Incorporación
Entré casi por casualidad. Conocí a Chema, CTO de Genially, unos años antes en una Pamplona Crafters y mantuvimos el contacto vía redes sociales (cuando tuiter aún molaba). Tiempo después, hablamos por otro tema y me propuso explorar si tenía sentido incorporarme. La compañía venía de crecer mucho y vieron que podía asumir un rol que resultase complementario.
Justo era un momento en el que empezaba a sentir que necesitaba un cambio profesional, pero quería estar seguro de mi siguiente paso. Así que tras haber hecho el proceso de selección, nos tomamos un par de meses y tuvimos varias conversaciones hasta que finalmente me incorporé a la compañía.
Entré con un rol de Platform Lead, por lo que mi responsabilidad iba a ser ayudar a los equipos de producto a que pudieran enfocarse en tener impacto, tratando de mejorar la experiencia de desarrollo y la efectividad de los equipos. Como bonus, también iba a echar una mano en cuestiones más organizativas.
Aunque este era un rol de liderazgo, no había un equipo dedicado, de modo que iba a tener que influir, colaborar con distintos equipos y empujar algunas iniciativas por mi cuenta.
Una vez hecho el onboarding, empezar a tener algunas iniciativas ya lanzadas y conociendo más la compañía, traté de aterrizar una serie de metas:
Las iniciativas y actividades de plataforma deben facilitar la Developer Experience y ayudar a los equipos en distintos aspectos:
- Reducir su carga cognitiva, que se enfoquen en complejidad intrínseca y no en la extrínseca, potenciando la germana (generando aprendizaje, construyendo esquemas o automatizando su uso)
- Habilitar actitudes data-informed en la toma de decisiones
- Aportar la mayor autonomía y empoderamiento posibles
- Tratar de ser lo más eficientes en cuestiones de costes económicos
- Dar fiabilidad, que las herramientas apenas fallen
Metas que traté de tener en cuenta, definiendo e implantando prácticas, procesos y herramientas, automatizando tareas, creando documentación… Y darles seguimiento unas veces de manera cuantitativa y otras de forma cualitativa.
Algunas de las iniciativas más relevantes fueron estas:
- Actuar como puente entre el equipo de infraestructura y los equipos de producto para acelerar la implantación del stack de observabilidad de Grafana (Loki, Mimir, Tempo).
- Formalizar la redacción de postmortems blameless tras incidencias que afecten al servicio junto a CTO y VP de ingeniería, para fomentar el aprendizaje sistémico.
- Apoyar al equipo de Design System con distintas actividades.
- Ayudar en la introducción de Snowplow + Amplitude para la instrumentación de producto colaborando con el equipo de data y los primeros equipos de producto involucrados.
- Introducir el uso de Turborepo en el monorepo para simplificar el proceso de build.
- …
A nivel organizativo
Durante esos primeros meses se estaba planteando una reorganización del área de desarrollo de producto bastante importante. Básicamente era pasar de una estructura de squads que se organizaba de forma recurrente a una basada en líneas de trabajo que tuvieran continuidad en el tiempo.
Esto fue algo en el que me involucraron aún sin tener mucho contexto junto al resto de managers de tech y producto, en parte venía bien tener a alguien con mirada limpia aunque en ocasiones pudiera pecar de ingenuo, para cuestionar supuestos y detectar disonancias.
En aquel entonces me resultó muy útil que alguna de la gente involucrada en la reorganización estuviera hablando en términos de Team Topologies, porque nos ayudaba a tener un lenguaje común. Eso lo terminamos enfrentando con un ejercicio de Context Mapping (en un par de eventos charlé sobre ello), donde representamos buena parte del funcionamiento de la compañía para ver el encaje de equipos respecto a la situación actual.
Este ejercicio sirvió para completar la foto real a la que íbamos, e incluso permitió detectar potenciales problemas de bounded contexts en los que había muchas manos y algunas en las que había muy pocas. Así que cuando con el paso del tiempo surgieron algunos problemas relacionados, no nos pilló tan por sorpresa.
Además, institucionalizamos el dar seguimiento a lo que surgía de las retros de los equipos, ya que se estableció como práctica que se documentase por escrito al menos lo más destacado de ellas y las acciones que surgieran. Esta práctica se mantiene a día de hoy, y resulta muy útil a la capa de management como complemento a los 1:1s para detectar fricciones y puntos de mejora.
Mucho de esto y algunas cosas más, las compartí en la charla Desarrollo de producto en una Scale-Up precisamente en la Pamplona Crafters 2024.

Volviendo a hacer producto (interno)
Tras un año, mi foco cambió a ser algo más todoterreno. Por un lado, ya tenía bastante controladas las dinámicas en el área de desarrollo de producto y a nivel de plataforma había aún puntos de mejora en los que iba trabajando, pero estábamos ya más en una fase de mejora continua y constante, además el equipo de infraestructura seguía introduciendo grandes mejoras. Mientras tanto, en otras áreas de la compañía se identificaban problemas mayores con los que creíamos que podía aportar más.
Ventas
Uno que terminó surgiendo fue en el equipo de ventas, al que había que buscarle solución de forma prioritaria, ya que ninguna de las líneas de trabajo a priori tenía foco en ese tema. Teníamos un proceso interno ineficiente y propenso a errores que terminaban sufriendo clientes High Touch de gran tamaño: muchos emails y llamadas de coordinación, uso de spreadsheets de gestión, tiempos de espera por parte de clientes y account managers, etc.
Para solventar el problema se decidió montar un squad específico moviendo a algunos perfiles técnicos desde algunas líneas de trabajo, y como no queríamos sacar de foco a product managers terminé involucrado en la fase de discovery para abordarlo.
Así que tocó entender los problemas que el equipo de ventas se estaba encontrando y, junto a compañeras de customer experience, entrevistarnos con clientes y gente del área de ventas. A partir de ahí, documentar el impacto que estaba teniendo, definir un primer alcance del MVP usando un user story map y preparar un kick-off para tener tanto al squad, stakeholders y el resto de la compañía alineados.
El squad trabajó en una herramienta que diera mayor autonomía a esos clientes de gran tamaño, permitiendo a account managers mantener el control y darles seguimiento. Y en mi caso, aunque no tiré ni una línea de código y que luego me quedase acompañando al squad de lejos casi como un stakeholder más, me lo pasé como un enano volviendo a participar en hacer producto en fases iniciales.
Creativo
Tiempo más tarde, nos encontrarnos otro problema importante en el área de creativo. Uno de los valores que ofrece Genially a las personas usuarias son las plantillas diseñadas por este equipo. Nos encontramos con un problema de atasco en la publicación de nuevas plantillas y cambios en las existentes que antaño no ocurría, el producto había evolucionado de un modo en el que terminó afectando en la operativa diaria de este equipo.
Esto es porque una vez diseñadas, existía un cuello de botella en el proceso de publicación tanto en el producto como en la web pública. Esta ineficiencia en el Go to Market provocaba tardar más tiempo en recuperar la inversión, era propenso a errores y frustraba a las personas de ese equipo.
Al final era un problema para el que la perspectiva Lean encajaba como anillo al dedo: Identificar el valor, mapear el flujo de trabajo, mantener un flujo continuo, aplicar sistema pull y buscar la mejora continua. Para lo cual se decidió crear de nuevo un squad que se enfocara en esta área.
Una vez analizado y mapeado el journey principal que queríamos resolver, habiendo identificado los distintos hand-offs y limitaciones de las herramientas, planteamos crear un nuevo backoffice diseñado para habilitar mayor autonomía y que simplificase su proceso. De ese modo podríamos sustituir de forma incremental el backoffice legacy, un CMS y un par de spreadsheets de gestión.
Para acelerar el proceso de publicación introdujimos: soporte i18n, gestión de estados, uso de IA generativa, mejoras en las validaciones… Además de crear un servicio que pudiera consumirse desde el producto y la web, cosa que evitaba el uso de herramientas externas y, a nivel técnico, simplificaba la infraestructura y la mantenibilidad futura.
Una vez eliminado ese cuello de botella, que con la combinación del trabajo del squad con el equipo creativo pasó de un retraso de 4 meses a estar al día, nos centramos en mover y mejorar el resto de procesos que se soportaban aún en el legacy en esta nueva herramienta, y en el camino colaborar con uno de los equipos de producto para introducir algunas mejoras conjuntamente.
Operaciones y tech
Aproximadamente el último año en Genially mi rol terminó pivotando de manera oficial a trabajar con foco en las operaciones internas de la compañía. Esto significaba estar en un punto medio entre tecnología, producto, negocio, organización y su potencial impacto en la operativa diaria de cualquier área de la compañía. Esto implicaba mucha amplitud y normalmente menor profundidad, mucha comunicación, intentar promover iniciativas que tuvieran sentido o frenar las que aparentemente necesitasen reflexionarse más, identificar posibles problemas entre áreas de forma prematura, moverme todavía más habitualmente entre diferentes grados de abstracción, etc.
Siempre con una perspectiva de desarrollo de producto, durante ese tiempo tuve oportunidad de trabajar de nuevo y esta vez mucho más involucrado con el área de ventas y desarrollo de negocio; además de empezar a hacerlo también con las de financiero, personas, soporte y comunidad.
Trabajando con más áreas
Con el área de ventas empezamos a trabajar en hacer crecer el MVP que arrancamos antaño, soportando nuevas casuísticas primero y luego acercando e integrando esta herramienta con el CRM que se usa en la compañía. En mi caso había estado involucrado en el día a día de la línea de trabajo que lo evoluciona, con un rol de facilitador y ocasionalmente de desatascador.
Junto a las áreas de financiero y personas hicimos pequeñas iniciativas coordinadas con líneas de trabajo de producto, aunque algunas más ambiciosas se quedaron en el tintero porque el coste de llevarlas a cabo las hacían inviables al menos en el medio plazo.
Con soporte empecé a trabajar muy de cerca, ya que había una tormenta perfecta de cambios en el producto, iteraciones de negocio, atasco en los tiempos de respuesta y degradación de la experiencia de cliente.
Lanzamos varias acciones para solventar la situación: mejorar flujos en el chatbot, rehacer la integración con la herramienta de soporte para enriquecer la información de clientes y mejorar la gestión de colas, introducir automatizaciones, contratar e integrar a un proveedor para pasar a tener un chat basado en agentes de IA que escalase sólo casos complejos, etc. Una vez recuperada una situación de normalidad pudimos entrar en un modo de mejora continua en soporte, y poder dedicar más tiempo a iniciativas relacionadas con comunidad.
Y en medio de todo esto apoyar en ajustes organizacionales, tanto a nivel de desarrollo de producto como en el resto de áreas; y en iniciativas transversales, por ejemplo y para sorpresa de nadie, últimamente con foco en un par relacionadas con IA generativa.

Conclusión
Aunque al inicio costó un poco ver cómo gestionar ese tipo de rol pendular en el que a veces era difícil manejar la cantidad de cambios de foco y de niveles de abstracción, se me dio siempre confianza y autonomía. Finalmente me sentí muy cómodo con ese tipo de responsabilidades.
Me permitió poder influir a nivel organizativo como un manager primero a nivel de área y luego tratar de hacerlo a nivel de compañía, aunque sin las responsabilidades de gestión de personas. Y de vez en cuando poder ejecutar trabajo directamente por ejemplo programando, documentando o investigando de forma autónoma o colaborando con más personas en equipo.
Tras tener la oportunidad de trabajar con tanta gente diferente y variedad de áreas en el contexto de una scale-up, cierro esta etapa en Genially habiendo crecido mucho profesionalmente y con un montón de aprendizajes: técnicos, organizativos, de personas, de negocio… y siendo un fan de la marca y la compañía.
Y ahora ¿qué?
Toca arrancar una aventura nueva que no esperaba, uno de esos trenes que sientes que son una gran oportunidad que tienes que tomar, pero eso lo cuento un poco más adelante en otro post.