Jugando con MCP protocol. Añadiendo bus, bizi y geocoding a MCP DNDzgz
Tras mis primeras pruebas jugando con MCP sólo con la información del tranvía de Zaragoza, decidí dar el siguiente paso y añadir los otros servicios que históricamente ha soportado DNDzgz: autobús urbano y el servicio bizi, el alquiler de bicicletas municipal. Y con eso completar el soporte de los tres servicios públicos de movilidad más esenciales y usados en el día a día de las personas que viven o visitan la ciudad.
El soporte al servicio de bus en DNDzgz llevaba roto desde un cambio de contrata, por el que un scraper llevaba tiempo sin funcionar. Eso lo descubrí usando la versión web móvil en una de mis últimas visitas a Zaragoza, pero no le había dedicado tiempo hasta ahora. Una vez resuelto ese problema, volví a jugar con las tools de MCP usando Cursor para ir modificando y probando.
Añadiendo el soporte de bus y bizi, encontrando límites
La implementación fue bastante directa, al ser algo tan sencillo le iba pidiendo al agente de Cursor que me generase el código para las tools de servicio de bizi y bus, tanto traer las posiciones como obtener la respuesta de los datos de estimación o disponibilidad en tiempo real.
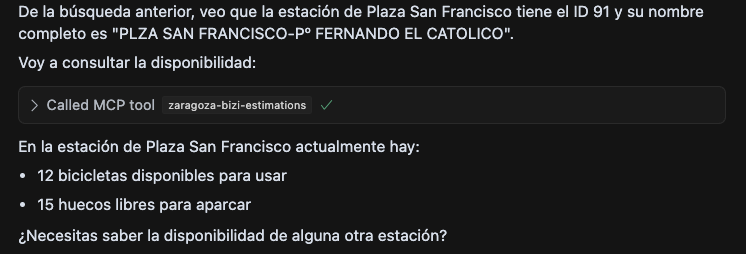
Sobre la marcha se me ocurrió que ya que el API de DNDzgz tiene información geolocalizada, podría estar bien un modo de conocer la ubicación rápidamente, así que añadí una nueva tool para que genere un enlace a google maps usando las coordenadas.
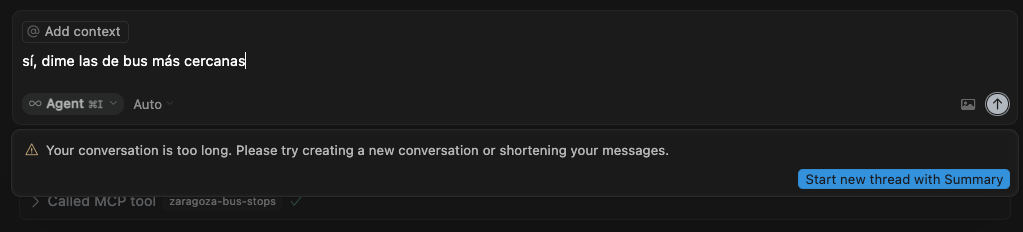
El problema apareció con el servicio de autobuses, que daba un error por terminar siempre con una conversación excesivamente larga. Esto se debía a que esta llamada devolvía una respuesta con un array JSON con unos pocos miles de objetos, cosa que tampoco es lo ideal pensando en los costes que tienen asociados estos LLMs con el consumo de tokens. Y como las pruebas siempre las he ido haciendo con cuentas gratuitas, esto se hizo evidente con este escenario.
Por ejemplo por parte de Cursor no encontré documentación del límite pero la respuesta está clara. “Your conversation is too long”
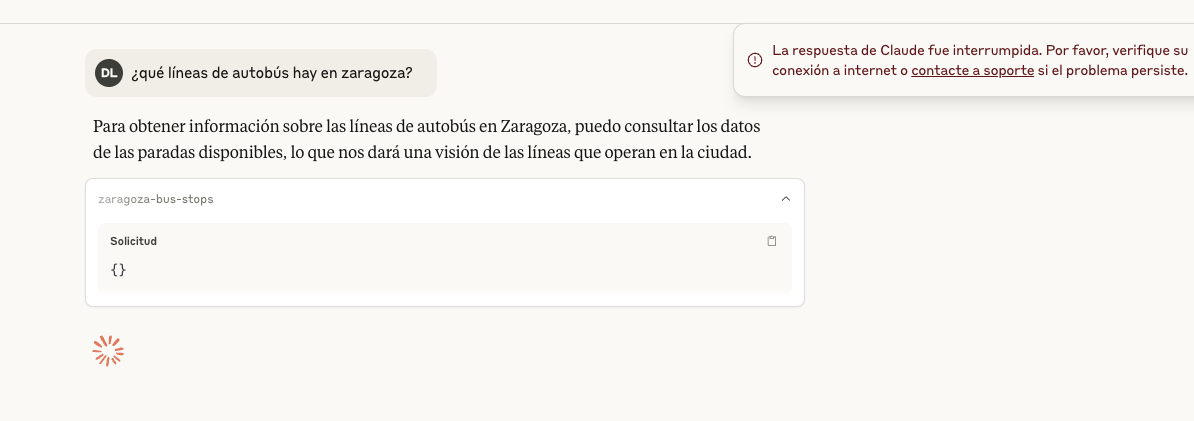
Mientras Claude Desktop daba un error más raro, sobre que la respuesta fue interrumpida. Pero en su caso sí lo tienen documentado: How large is Claude’s Context Window?
Tratando de reducir el tamaño de respuesta
Así que para salir del paso empecé a pensar cómo aligerar el tamaño de respuesta intentando no tener que tocar nada del API de DNDzgz, limitando los cambios al MCP server.
Como primer paso traté de ajustar la respuesta a lo mínimo necesario. Quitar el único atributo de la respuesta que no se usaba y filtrar resultados de paradas que sabía que no tienen realtime, ya que son del transporte metropolitano y no del urbano. Esto se podía intentar identificar con las líneas en cada parada al seguir esta patrones diferentes en su nomenclatura.
Eso era un poco cutre y aún así el tamaño de respuesta se mantenía muy alto. Debía intentar encontrar una manera de afinar lo máximo posible lo que devolvía MCP DNDzgz para evitar responder con cientos o miles items en las peticiones recibidas.
Con eso en la cabeza lo dejé reposar durante unos días, finalmente se me ocurrieron otras 2 soluciones:
En un primer momento pensé en la posibilidad de tratar de montar un filtro sobre texto para devolver el mínimo de estaciones o paradas posible. Dada la interfaz conversacional tenía la sensación que todo lo que no fuera una búsqueda de vectores para hacerlo de un modo semántico podía resultar una experiencia de usuario mediocre. Como es algo con lo que ya he experimentado un poco en otras pruebas de concepto, sé que podría haber jugado con el vector store en memoria de LangChaning y usar para los embeddings un proveedor externo o incluso añadir dependencia a Ollama.
Más tarde se me ocurrió otra opción, la búsqueda semántica es buena opción si sabes más o menos qué andas buscando. Pero dada la naturaleza de geolocalización de los servicios de movilidad lo más importante es el dónde lo andas buscando. Así que tal como están los datos expuestos en DNDzgz, veía que tenía más sentido ir por el camino de añadir una nueva tool que resuelva localizaciones y luego hacer búsquedas por posición. Esto parecía tener mucho sentido y estaba alieneado con el comportamiento que había visto en varias ocasiones de Claude, en el que el modelo me iba ofreciendo estimaciones en posiciones cercanas.
Solución desde la experiencia de uso de DNDzgz
Parece que tiene bastante sentido pedir cosas como “¿Dónde puedo coger el 30 en la zona de Paseo de la Independencia?”, “Estoy en el Parque Bruil, ¿dónde tengo bicis disponibles cerca?” a un asistente con interfaz conversacional. Al final son los tipos de respuestas que intentamos responder ya en tiempos del AbreDatos 2010 con una interfaz pensada para usarse en un teléfono móvil.
Con esta idea tiré por lo ya conocido, el API de Google Maps para geocoding, aunque podría haber tirado también por cualquier otro proveedor. Y exponerlo como otra tool, intentando forzar que siempre busque concatenando al valor recibido Zaragoza, Spain.
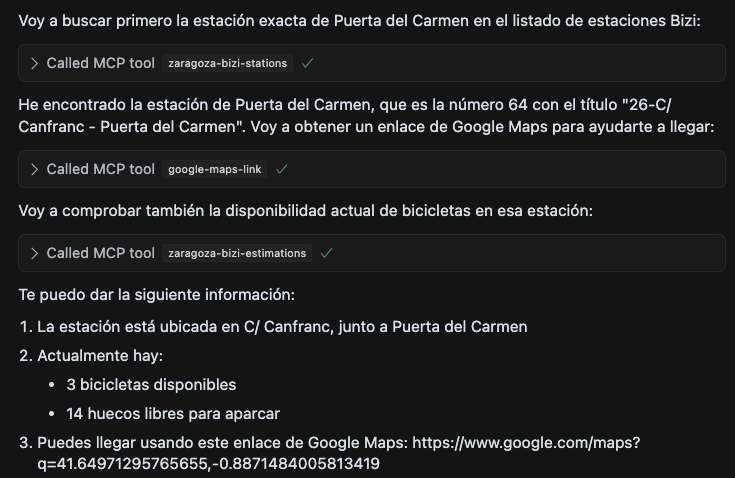
Tras eso las respuestas eran ya prometedoras, ya que parece que estos modelos trabajan bastante bien con posiciones geolocalizadas. Por ejemplo preguntándole sobre paradas de bicis cerca de la Avenida Madrid decía esto.
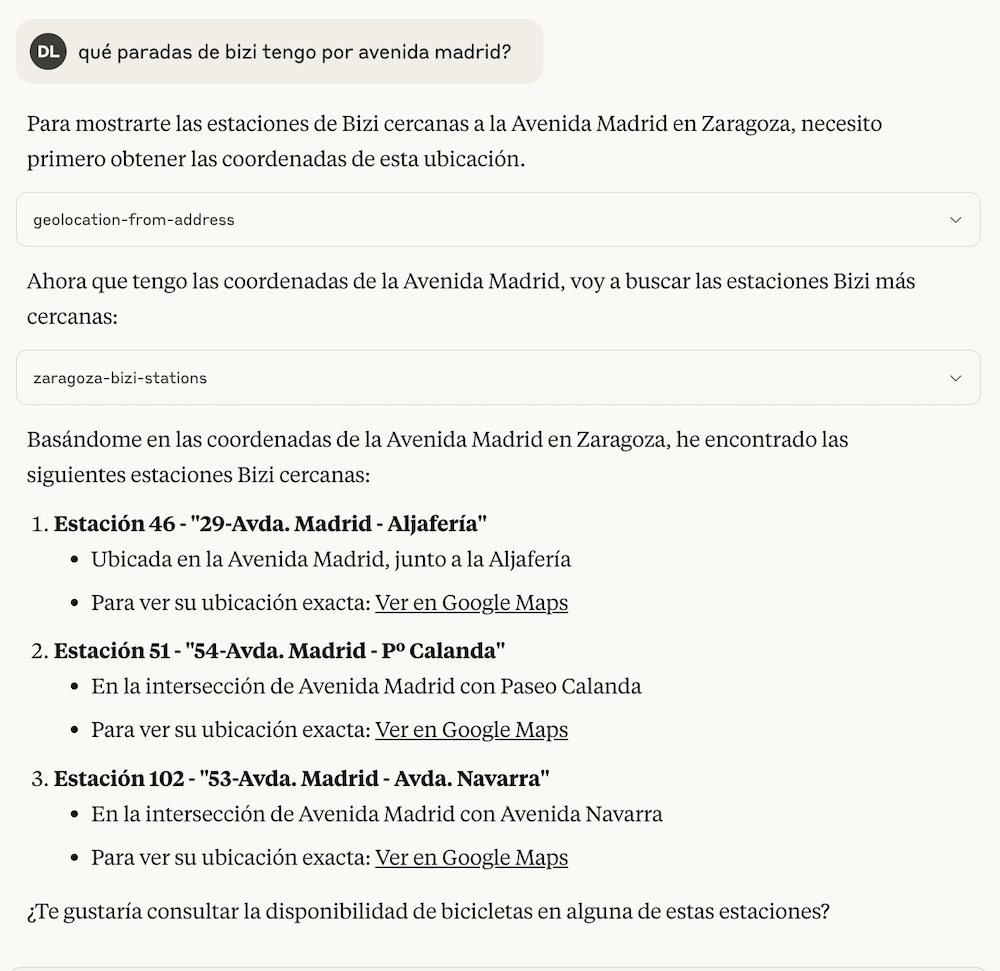
Todavía en este momento se devolvían las más de 100 estaciones de bizi que hay disponibles, y en el caso de los buses eran más de 1000. Lo siguiente era pasar la posición dada a partir de una dirección a las tools que traen las ubicaciones con sus respectivas posiciones, comprobar la distancia entre posiciones usando una implementación de la fórmula de Harversine, ordenarlas por cercanía y devolver un top razonable para que los LLMs hagan lo suyo.
Una vez implementado eso, dejando el límite a 10, se acotan mucho los resultados y la experiencia aparentemente era algo mejor. Ahora ordenando por distancia entre los puntos e informa sobre ello, además se ofrecen otras opciones indicando lo lejos del punto de referencia.
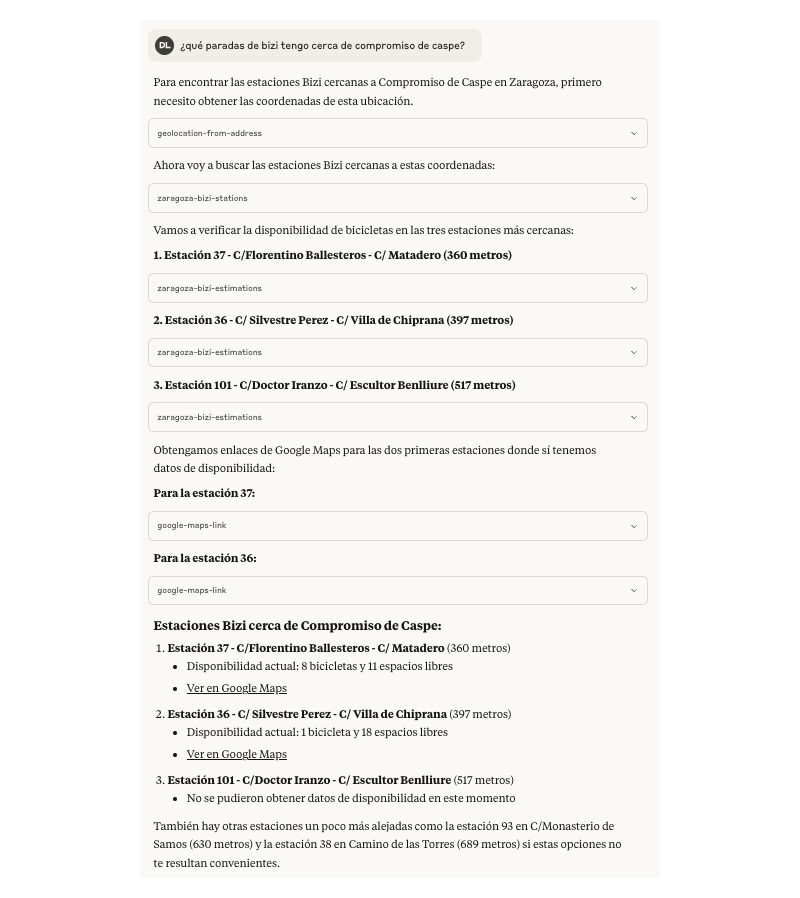
A partir de ahí el problema del tamaño del bus dejó de serlo.
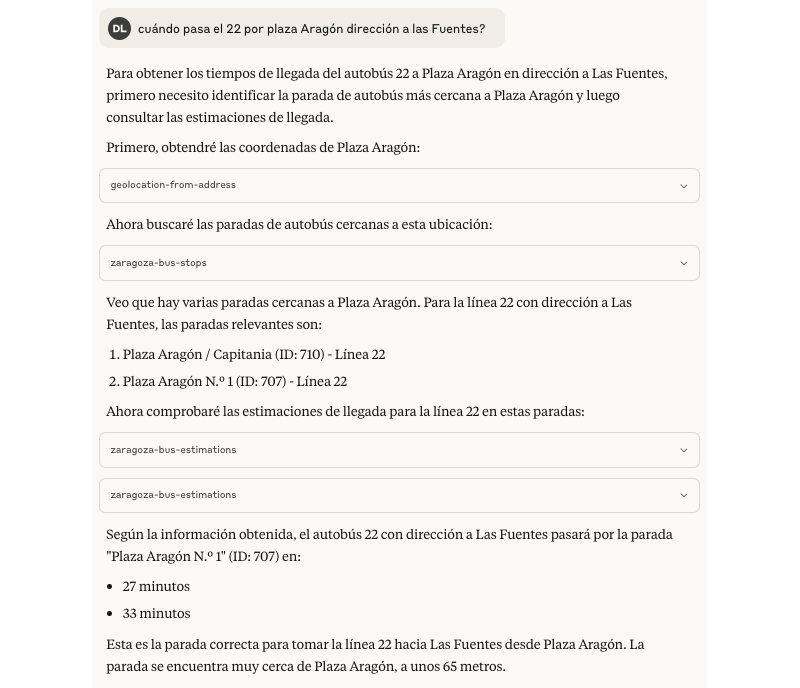
Durante mis pruebas me encontré que Claude intenta llamar varias veces a las tools en ocasiones donde considera que las distancias son alejadas o cuando no consigue obtener datos del estado en tiempo real, está claro que no le gusta quedar mal 🙂. Por ejemplo con esta prueba preguntando sobre una línea de bus en una dirección.
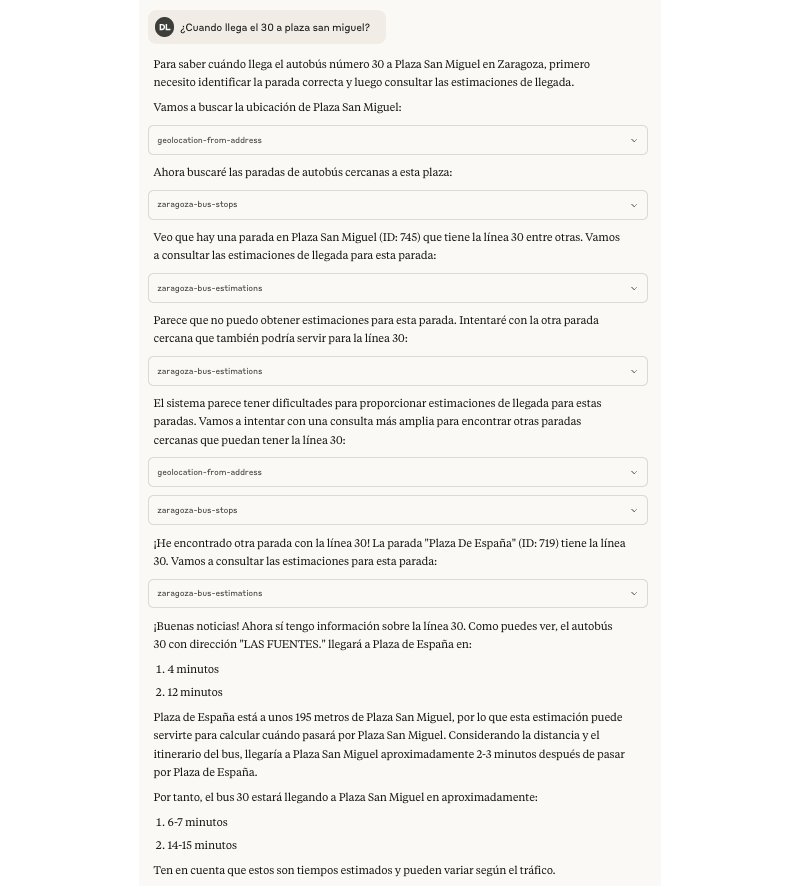
También para variar y ver más comportamientos, hice alguna prueba con GitHub Copilot y GPT-4o en modo agente, con los que la experiencia a priori me resultó bastante similar.
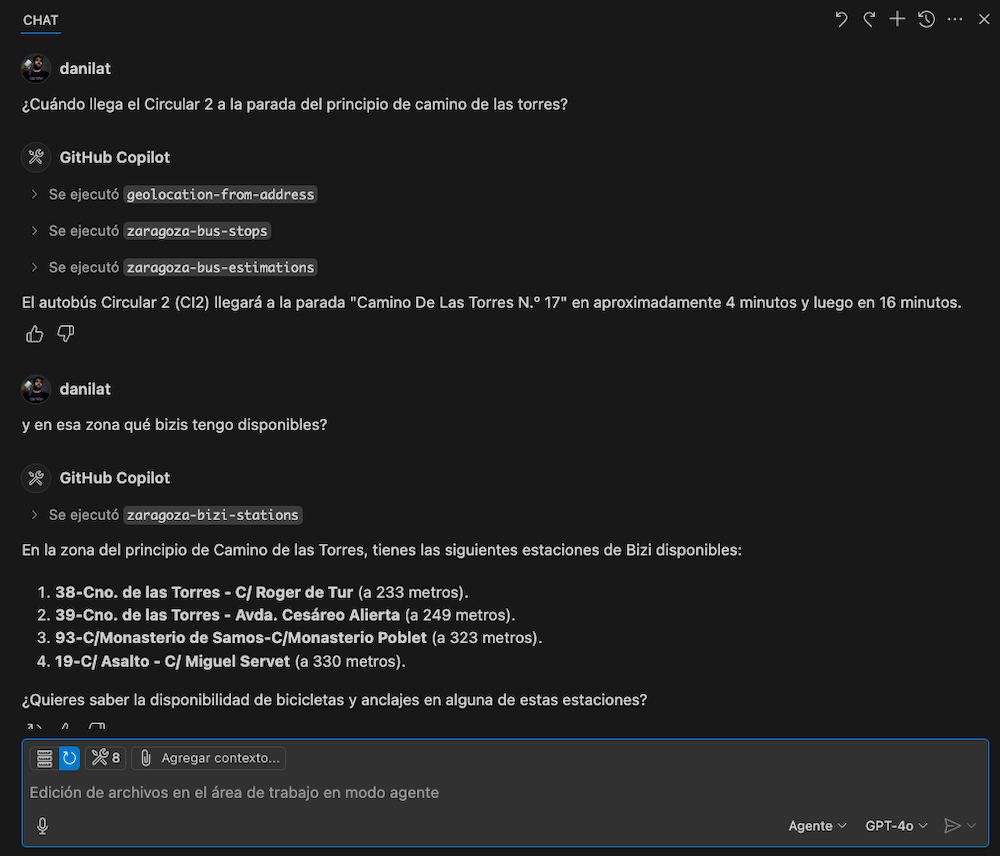
Hay otras tools que podrían llegar a ser muy útiles y serían complementarias, por ejemplo para cubrir casuísticas de recomendar de cómo llegar de un punto a otro de la ciudad en transporte público. Ya que los datos con los que fueran entrenados los modelos pueden haber quedado desactualizados o puede que se los estén inventando.
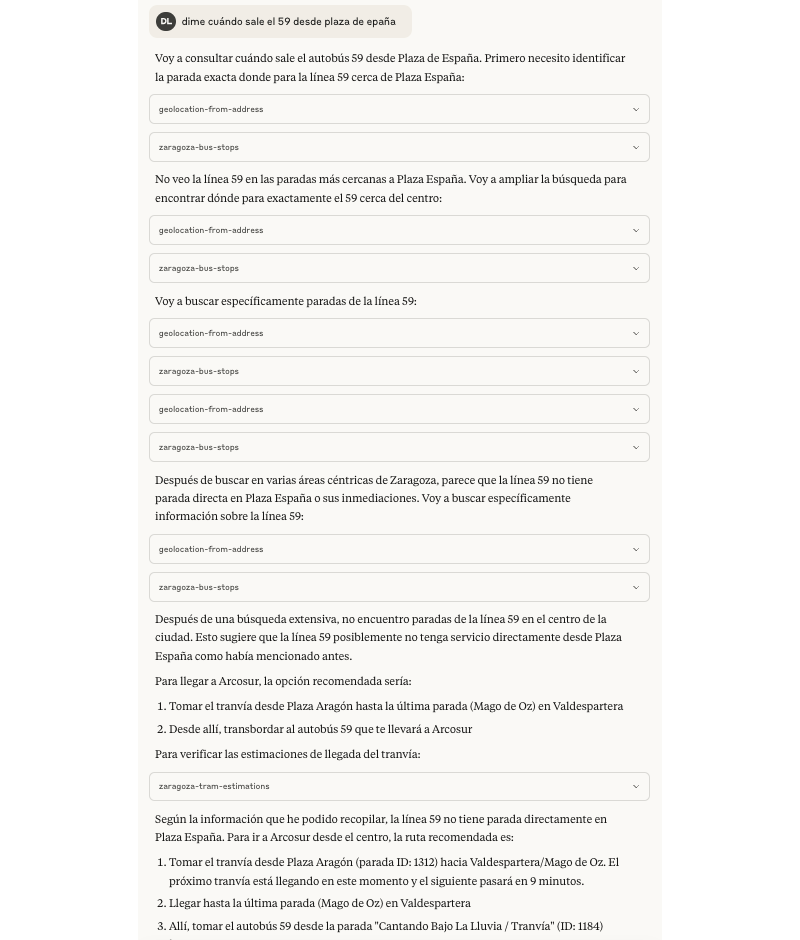
Por ejemplo, al preguntarle cómo llegar de Plaza Aragón a Arcosur en tranvía me decía correctamente que a Arcosur no llega el tranvía y que tendría que hacer transbordo tras la última parada. Pero me ofrecía como alternativa sin trasbordo la posibilidad de la línea de bus 59 desde Plaza de España, al pedirle las estimaciones terminó dándose cuenta que esa opción no existe por sí mismo.
Conclusiones
Este experimento con tools de MCP para darles capacidades extra a los LLMs me ha resultado muy entretenido. En esta evolución he intentado darle un enfoque de solución un poco más de producto y no quedarme meramente en probar el protocolo.
He buscado soluciones pensando en las personas usuarias, aunque he hecho 0 investigación, sí he hecho memoria de feedback y críticas recibidas sobre las aplicaciones móviles de DNDzgz durante estos años.
Algunos pensamientos al respecto de este side-project:
- Las tools mucho mejor si envían respuestas ligeras, por cuestiones de eficiencia de red, coste, consumo energético, tiempos de respuesta, etc.
- Tratar de dar buenas descripciones a las tools para facilitar que los LLMs tengan más claro cuando usarlo respecto a las intenciones de las personas usuarias.
- Eat your own dog food como para cualquier side-project, salvo que sólo quieras cacharrear con la tecnología y luego olvidarte.
- Que alguien más lo pruebe te va a ayudar a mejorarlo, aunque no hagas test con personas usuarias al uso viene bien tener otros puntos de vista.
- Al usar directamente estos LLMs con estos clientes tratan de quedar bien, a veces eso significa que puedan alucinar. Así que lo suyo es facilitarles tools que puedan ayudarles a no hacerlo en los temas que nos competen.
- Como se van a buscar la vida para dar una respuesta, esto significa que pueden hacer muchas llamadas a su aire a nuestras tools sin que la persona que le ha pedido algo intervenga.
- Por esto último, ahora mismo me daría un poco de miedo el exponer acciones destructivas en una tool que no se puedan deshacer: Borrar documentos, sobreescribir información sin versionado, etc.
- Supongo que montando un chatbot especializado, con prompts de sistema para los LLMs y que actúe como cliente MCP, son potenciales problemas que se pueden solventar. A corto plazo dudo que me meta en ese fregao 😀.
Podéis ver el código de mcp-dndzgz en github con los cambios comentados en el artículo.